Orchestration HTCondor Plug-in Configuration Files¶
Note
Please note that the following information is only useful if you’re going to use the Orca utility directly. We recommend that you use the ctrl_execute package an runOrca.py to configure and run application code because it hides a lot of the configuration information below. It’s highly unlikely you’ll want to change this information directly.
The Condor plugin for Orca uses Config files to describe tasks that will be launched as Condor DAG jobs. The plugin uses Config files to fill in templates with information used to submit Condor jobs. All set up tasks and actual jobs that run are done through scripts, which we submit to Condor and execute on the target system.
The following is an example Config file, broken up into parts.
The structure of the Config file is similar to how the Policy file used to be. A lot of these can be changed. If they’re not explained below, they’re used internally, and can be left alone. These will become default values in the Config objects, and won’t need to always be specified.
#
# Example Orchestration Layer Config
#
config.production.shortName = "DataRelease"
config.production.eventBrokerHost = "lsst8.ncsa.uiuc.edu"
config.production.productionShutdownTopic = "productionShutdown"
shortName- The name of this productioneventBrokerHost- The host name which is running the ActiveMQ brokerproductionShutdownTopic- The topic used by Orca to send an event that the entire production should end.
config.database["db1"].name = "dc3bGlobal"
config.database["db1"].system.authInfo.host = "lsst10.ncsa.uiuc.edu"
config.database["db1"].system.authInfo.port = 3306
config.database["db1"].system.runCleanup.daysFirstNotice = 7
config.database["db1"].system.runCleanup.daysFinalNotice = 1
config.database["db1"].configurationClass = "lsst.ctrl.orca.db.DC3Configurator"
config.database["db1"].configuration["production"].globalDbName = "GlobalDB"
config.database["db1"].configuration["production"].dcVersion = "S12_sdss"
config.database["db1"].configuration["production"].dcDbName = "DC3b_DB"
config.database["db1"].configuration["production"].minPercDiskSpaceReq = 10
config.database["db1"].configuration["production"].userRunLife = 2
config.database["db1"].logger.launch = True
authInfo.host- host name of the database serverauthInfo.port- port number that the database server is listening on.
The authInfo values are used to match the dbAuth.py file, which is located in
the user’s $HOME/.lsst directory.
configurationClass- The Orca class should use to figure the databaseglobalDbName- The name of the Global DatabasedcVersion- Data challenge versiondcDbName- Database to write new tables intologger.launch- This indicates to Orca that it needs to launch the database logger to record logging events to the database.
config.workflow["workflow1"].platform.dir.defaultRoot = "/oasis/scratch/ux453102/temp_project/lsst"
config.workflow["workflow1"].platform.deploy.defaultDomain = "ncsa.illinois.edu"
config.workflow["workflow1"].configurationType = "condor"
config.workflow["workflow1"].configurationClass = "lsst.ctrl.orca.CondorWorkflowConfigurator"
config.workflow["workflow1"].configuration["condor"].condorData.localScratch = "/home/home/daues/orca_scratch"
config.workflow["workflow1"].task["task1"].scriptDir = "workers"
defaultRoot- the ‘’‘remote directory’‘’ which will be used to store run information. The “runid” that you specify on the Orca command line is appended to this directory and work is done in that resulting directory.defaultDomain- the domain of the local machine.configurationType- The type of job this is. Currently, values can be “condor”, “generic” and “vanilla”. The “generic” and “vanilla” types aren’t working because they rely on pex_harness and job office, which we currently not using.configurationClass- This is the name of the Condor plugin.condorData.localScratch- This is the ‘’‘local directory’‘’ where condor jobs are launched, and where local log file are written.
Condor glidein template¶
Note
Orca does not currently do automatic glidein requests, but may in the future. The template specification outlined below describes parameters that would typically be changed depending on the type of job that the user wanted to run.
Condor glidein requests are done for jobs that which to use remote resources of another cluster, such as one of the XSEDE systems. If Orca uses the local cluster, a glidein does not need to be specified.
The templating system for the glidein template file allows the user to create arbitrary keywords in a template, which are then substituted with values in the config file.
The keywords are marked with a prefixed dollar sign $.
For example, the template file:
#!/bin/bash
# Sample Batch Script for a Serial job
#
# Submit this script using the command: qsub <script_name>
#
# Use the "qstat" command to check the status of a job.
#
# The following are embedded QSUB options. The syntax is #PBS (the # does
# _not_ denote that the lines are commented out so do not remove).
#
# walltime : maximum wall clock time (hh:mm:ss)
#PBS -l walltime=$MAX_CLOCK
#
# nodes: number of 16-core nodes
# ppn: how many cores per node to use (1 through 16)
# (you are always charged for the entire node)
#PBS -l nodes=$NODE_COUNT:ppn=$SLOTS
#
# export all my environment variables to the job
### #PBS -V
#
# job name (default = name of script file)
#PBS -N $NODE_SET
# -------------------------------------------------- shimem1
#PBS -q $QUEUE
#
##
# Send a notification email when the job (b)egins and when the (e)nds
# # remove the line below to disable email notification.
$EMAIL_NOTIFICATION
# #
# #
# # filename for standard output (default = <job_name>.o<job_id>)
# # at end of job, it is in directory from which qsub was executed
# # remove extra ## from the line below if you want to name your own file
#PBS -o $SCRATCH_DIR/$OUTPUT_LOG
# #
# # filename for standard error (default = <job_name>.e<job_id>)
# # at end of job, it is in directory from which qsub was executed
# # remove extra ## from the line below if you want to name your own file
#PBS -e $SCRATCH_DIR/$ERROR_LOG
#
# #
# # End of embedded QSUB options
# #
# # set echo # echo commands before execution; use for debugging
# #
#
# set JOBID=`echo $PBS_JOBID | cut -d'.' -f1`
#
# # cd $SCR # change to job scratch directory
/bin/echo $PBS_JOBID
/bin/echo Beginning_Glidein_Setup
hostname -f
hostcnt=0;
while read line
do
hostcnt=`expr $hostcnt + 1`;
hostname[$hostcnt]=$line
done < "$PBS_NODEFILE"
echo "names are:"
for num in $(seq 1 $hostcnt)
do
echo ${hostname[$num]}
done
for num in $(seq 1 $hostcnt)
do
ssh ${hostname[$num]} 'hostname -f' &
done
wait
for num in $(seq 1 $hostcnt)
do
ssh ${hostname[$num]} 'export CONDOR_CONFIG=$CONDOR_CONFIG;export _condor_CONDOR_HOST=$CONDOR_HOST;export _condor_GLIDEIN_HOST=$CONDOR_HOST;export _condor_LOCAL_DIR=$CONDOR_LOCAL_DIR;export _condor_SBIN=$CONDOR_SBIN;export _condor_NUM_CPUS=$CPU_COUNT;export _condor_UID_DOMAIN=$CONDOR_UID_DOMAIN;export _condor_FILESYSTEM_DOMAIN=$FILESYSTEM_DOMAIN;export _condor_MAIL=/bin/mail;export _condor_STARTD_NOCLAIM_SHUTDOWN=$STARTD_NOCLAIM_SHUTDOWN; $GLIDEIN_STARTUP_COMMAND' &
done
wait
date
The keywords are:
$CONDOR_SBIN$JOB_NAME$CPU_COUNT$MACHINE_COUNT$MAX_WALLTIME$QUEUE$PROJECT$FILESYSTEM_DOMAIN$CONDOR_CONFIG$GLIDEIN_STARTUP_COMMAND$CONDOR_HOST$CONDOR_LOCAL_DIR$CONDOR_UID_DOMAIN$STARTD_NOCLAIM_SHUTDOWN
Here’s how this section of the Config file is set up:
config.workflow["workflow1"].configuration["condor"].glidein.template.inputFile = "$CTRL_ORCA_DIR/etc/condor/templates/nodes.pbs.template"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["CONDOR_SBIN"] = "/oasis/projects/nsf/nsa101/srp/condor/condor-7.4.4-r1/sbin"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["JOB_NAME"] = "lsst_job"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["CPU_COUNT"] = "12"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["MACHINE_COUNT"] = "2"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["MAX_WALLTIME"] = "00:30:00"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["QUEUE"] = "normal"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["PROJECT"] = "TG-AST100018"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["FILESYSTEM_DOMAIN"] = "sdsc.edu"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["CONDOR_CONFIG"] = "/oasis/projects/nsf/nsa101/srp/condor/glidein/glidein_to_launch2_condor_config"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["GLIDEIN_STARTUP_COMMAND"] = "/oasis/projects/nsf/nsa101/srp/condor/glidein/glidein_startup_gordon -dyn -f"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["CONDOR_HOST"] = "lsst-launch.ncsa.illinois.edu"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["CONDOR_LOCAL_DIR"] = "/home/srp/condor_local"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["CONDOR_UID_DOMAIN"] = "ncsa.illinois.edu"
config.workflow["workflow1"].configuration["condor"].glidein.template.keywords["STARTD_NOCLAIM_SHUTDOWN"] = "1800"
config.workflow["workflow1"].configuration["condor"].glidein.template.outputFile = "nodes.pbs"
template.inputFile: The name of the template to use to substitute keywordstemplate.keywords: Array containing keyword/value pairs. Please note these are all strings, and must be enclosed with quotes.template.outputFile: The name of the file to write as output, once the keywords are replaced in the template.
Remember that the keywords in the template and in the keywords list are completely user configurable. If the keyword appears in the template but doesn’t exist in the keyword list, it will remain as is. If the word is the the keyword list, but not in the template, nothing will be substituted.
HTCondor DAG¶
The Condor plugin creates a Condor Diamond DAG which it submits to be executed.
The structure for the DAG is simple:
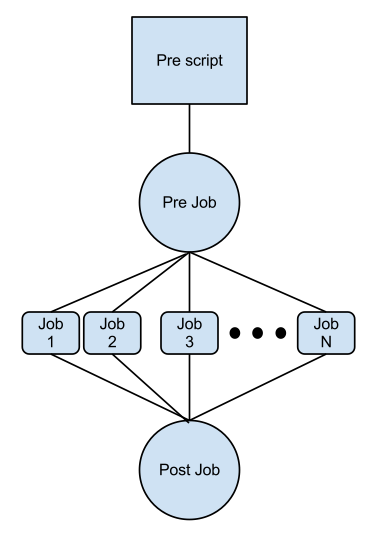
Execution:
When the DAG is submitted, this is the order in which it executes each part. I use the term “local” to mean the machine on which Orca was executed, and “remote” to be a job in the Condor pool.
1. The optional PreScript is a shell script that runs on the ‘’‘local’‘’ machine. Condor runs this before the first PreJob condor job it submits. The purpose of this is to allow you to run something locally if you need to have it set up for the rest of the DAG. This could be copying files, creating additional directories, etc.
2. After the PreScript is finished, the first job is submitted. We’ve named this the “PreJob”. This job executes on one of the ‘’‘remote’‘’ machines, one of the machines in the Condor pool. The purpose of this is to set up anything that needs to be set up on the remote machine before the real tasks are executed. This could be transferring files, creating remote directories, linking files, etc.
3. After the PreJob is finished, all the regular jobs are executed. How this is specified depends on the output of the DAG generator script (see below). In the example DAG generator on which this example is based, it takes input from a file and creates a single job for each line of input. So, if the input file contains 10,000 lines, it creates a single job for each line. All of these jobs are submitted to Condor.
4. Once all the jobs are executed, Condor submits a final job, the “PostJob”. This job can be used for whatever needs to be done after the job is completed. This could be gzipping the files, transferring results, etc.
Templates¶
There are many, many different parameters that can be changed in Condor jobs and in the scripts that execute in those jobs. In fact, the DAG itself might need structurally different than what was outlined above. For example, after the PreScript and PreJobs are done, you might want to have a small set of jobs execute, wait for them all the complete, and then another small set of jobs execute. In order to maintain maximum flexibility for this, Orca’s Condor plugin has an outline of the DAG that is generated, but leaves what each individual shell script and condor job up to the user. These are all put into templates which Orca uses to then fill in job specific information like the RUNID, the defaultRoot. Currently the preScript preJob and postJob templates do not except external keywords.
config.workflow["workflow1"].task["task1"].scriptDir = "workers"
# this is used if we're running a script that runs LOCALLY before the
# preJob condor job is submitted.
config.workflow["workflow1"].task["task1"].preScript.script.inputFile = "$CTRL_ORCA_DIR/etc/condor/templates/preScript.template"
config.workflow["workflow1"].task["task1"].preScript.script.outputFile = "pre.sh"
scriptDir- this is the working directory where the generated condor files will be depositedpreScript.script.inputFile- This is a shell script template.preScript.script.outputFile- The new shell script that will be created.
Orca also supports keyword substitution in preJob, postJob and workerJob configurations.
#
# preJob
#
config.workflow["workflow1"].task["task1"].preJob.script.inputFile = "$DATAREL_DIR/dagutils/dag/sdss/ccd/dag/templates/preJob.sh.template"
config.workflow["workflow1"].task["task1"].preJob.script.keywords["USERHOME"] = "/home/ux453102"
config.workflow["workflow1"].task["task1"].preJob.script.keywords["USERNAME"] = "ux453102"
config.workflow["workflow1"].task["task1"].preJob.script.keywords["DATADIR"] = "/oasis/scratch/ux453102/temp_project/lsst/stripe82/dr7/runs"
config.workflow["workflow1"].task["task1"].preJob.script.keywords["EUPS_PATH"] = "/oasis/scratch/ux453102/temp_project/lsst/beta-0713/lsst_home"
config.workflow["workflow1"].task["task1"].preJob.script.keywords["LSST_HOME"] = "/oasis/scratch/ux453102/temp_project/lsst/beta-0713/lsst_home"
config.workflow["workflow1"].task["task1"].preJob.script.outputFile = "preJob.sh"
config.workflow["workflow1"].task["task1"].preJob.condor.inputFile = "$DATAREL_DIR/dagutils/dag/sdss/ccd/dag/templates/preJob.condor.template"
config.workflow["workflow1"].task["task1"].preJob.condor.keywords["FILE_SYSTEM_DOMAIN"] = "sdsc.edu"
config.workflow["workflow1"].task["task1"].preJob.condor.outputFile = "S2012Pipe.pre"
There are two sections to this preJob configuration: the shell script template
and the Condor template. Each has an inputFile containing the template, and
names an outputFile which will be written to disk. The keywords in each section
contain key/value pairs that Orca uses to substitute values in the templates.
For example, anywhere the value $FILE_SYSTEM_DOMAIN exists in
$DATAREL_DIR/etc/condor/templates/preJob.condor.template, the value
“sdsc.edu” will be substituted. You can make the key/value pairs whatever you
want. If they exist in the templates, they’re substituted. If they don’t exist
in the templates, they’re ignored. This works for both the script templates and
the Condor templates.
#
# postJob
#
config.workflow["workflow1"].task["task1"].postJob.script.inputFile = "$DATAREL_DIR/dagutils/dag/sdss/ccd/dag/templates/postJob.sh.template"
config.workflow["workflow1"].task["task1"].postJob.script.outputFile = "postJob.sh"
config.workflow["workflow1"].task["task1"].postJob.condor.inputFile = "$DATAREL_DIR/dagutils/dag/sdss/ccd/dag/templates/postJob.condor.template"
config.workflow["workflow1"].task["task1"].postJob.condor.keywords["FILE_SYSTEM_DOMAIN"] = "sdsc.edu"
config.workflow["workflow1"].task["task1"].postJob.condor.outputFile = "S2012Pipe.post"
The post job runs after all the worker jobs have completed.
#
# workerJob
#
config.workflow["workflow1"].task["task1"].workerJob.script.inputFile = "$DATAREL_DIR/dagutils/dag/sdss/ccd/dag/templates/worker.sh.template"
config.workflow["workflow1"].task["task1"].workerJob.script.keywords["USERHOME"] = "/home/ux453102"
config.workflow["workflow1"].task["task1"].workerJob.script.keywords["USERNAME"] = "ux453102"
config.workflow["workflow1"].task["task1"].workerJob.script.keywords["DATADIR"] = "/oasis/scratch/ux453102/temp_project/lsst/stripe82/dr7/runs"
config.workflow["workflow1"].task["task1"].workerJob.script.keywords["EUPS_PATH"] = "/oasis/scratch/ux453102/temp_project/lsst/beta-0713/lsst_home"
config.workflow["workflow1"].task["task1"].workerJob.script.keywords["LSST_HOME"] = "/oasis/scratch/ux453102/temp_project/lsst/beta-0713/lsst_home"
config.workflow["workflow1"].task["task1"].workerJob.script.outputFile = "worker.sh"
config.workflow["workflow1"].task["task1"].workerJob.condor.inputFile = "$DATAREL_DIR/dagutils/dag/sdss/ccd/dag/templates/workerJob.condor.template"
config.workflow["workflow1"].task["task1"].workerJob.condor.keywords["FILE_SYSTEM_DOMAIN"] = "sdsc.edu"
config.workflow["workflow1"].task["task1"].workerJob.condor.outputFile = "S2012Pipeline-template.condor"
The worker job template is used to create the shell script that is transferred
and run on the condor compute node. Let’s take a closer look at the example
template, workerJob.condor.template:
universe=vanilla
executable=$ORCA_SCRIPT
transfer_executable=true
Requirements = (FileSystemDomain == "$FILE_SYSTEM_DOMAIN") && (Arch != "") && (OpSys != "") && (Disk != -1) && (Memory != -1) && (DiskUsage >= 0)
should_transfer_files = YES
when_to_transfer_output = ON_EXIT
notification=Error
args=$(var1)
output=logs/$(visit)/worker-$(var2).out
error=logs/$(visit)/worker-$(var2).err
remote_initialdir=$ORCA_DEFAULTROOT/$ORCA_RUNID
queue 1
This is a template of a simple condor submit file that dagman will use to submit jobs. This is where the actual work gets done.
There are a couple of things of note here. First, anything that starts with
$ORCA_ is a reserved word for Orca, and should be left alone. Orca
substitutes the correct values for the script, default root and the run id from
the information it has. Second, the “Requirements” line in this script is used
by Condor to match machines with jobs.
Requirements = (FileSystemDomain == "$FILE_SYSTEM_DOMAIN") && (Arch != "") && (OpSys != "") && (Disk != -1) && (Memory != -1) && (DiskUsage >= 0)
The main restriction here is that the FileSystemDomain of the machine must
match what we want to use; in this case, our FILE_SYSTEM_DOMAIN keyword
will be substituted by Orca with “sdsc.edu” because of this line:
config.workflow["workflow1"].task["task1"].workerJob.condor.keywords["FILE_SYSTEM_DOMAIN"] = "sdsc.edu"
Additional requirements can be added to this line.
Note
FILE_SYSTEM_DOMAIN
The keyword “FILE_SYSTEM_DOMAIN” is used to specify the compute node’s domain. This is used to differentiate where the job will actually run. For example, we have a local cluster, and all the nodes on that cluster are in the “illinois.edu” domain. If we do a glidein from one of the XSEDE clusters in San Diego, those nodes are in the “sdsc.edu” domain. If we want to target ONLY machines on the local cluster, we specify “illinois.edu” for FILE_SYSTEM_DOMAIN. If we want to target ONLY the nodes from San Diego that we brought in from the glidein request, we specify “sdsc.edu”.
Your version of the *.condor.templates might not have this included, and
you might have a line that looks like this:
Requirements = (FileSystemDomain != "") && (Arch != "") && (OpSys != "") && (Disk != -1) && (Memory != -1) && (DiskUsage >= 0)
and if that’s the case, the job will run on any available condor node that machines this. Check this is if you want to run on specific machine domains (ie, illinois.edu, sdsc.edu, etc).
Note
DAG generation
Once Orca fills in the templates above, it generates a Condor DAGman file mentioned above. The config file specifies how the DAGman script is parameterized:
config.workflow["workflow1"].task["task1"].dagGenerator.dagName = "S2012Pipe" config.workflow["workflow1"].task["task1"].dagGenerator.script = "$DATAREL_DIR/dagutils/dag/sdss/ccd/dag/scripts/newgenerateDag.py" config.workflow["workflow1"].task["task1"].dagGenerator.idsPerJob=19 config.workflow["workflow1"].task["task1"].dagGenerator.input = "/lsst/home/daues/work/S2012/InputData/initialBatch/ccdlist"
Where:
dagNameis the name of the DAGscriptis the DAG generator scriptidsPerJobis the number of ids that will be given to each jobinputis the list of job to do.
In this case, the input is:
run=1056 camcol=4 filter=g field=173
run=1056 camcol=4 filter=g field=174
run=1056 camcol=4 filter=g field=175
run=1056 camcol=4 filter=g field=176
run=1056 camcol=4 filter=g field=177
... etc ....